

- Aller sur le site de Node JS et télécharger la dernière version LTE pour Windows.
- Exécuter l’installation à partir du fichier msi précédemment télécharger. Suivre la procédure en installant les éléments proposés par défaut. Ici Node JS sera installé dans le répertoire « C:\Program Files\nodejs:\node« .
- Créez le répertoire qui va accueillir les fichiers d’exercices développés pendant la formation. Ici, « c:\dev\nodejs-1-2-fondamentaux »
- Lancer Visual Studio Code. Sélectionner le menu « Fichier / Ajouter un dossier à l’espace de travail… ». Renseigner le dossier créé dans l’étape précédente.
- Dans VSCode, afficher la fenêtre « terminal » (touches Ctrl+ù).
- Dans la fenêtre du terminal :
- Se placer dans le dossier de développement : « cd c:\dev\nodejs-1-2-fondamentaux »
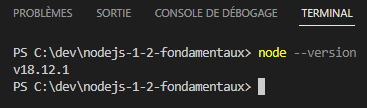
- Entrer la commande « node –version » pour vérifier que l’installation c’est correctement déroulée. En réponse de la commande exécutée, le numéro de version installé doit être affiché.
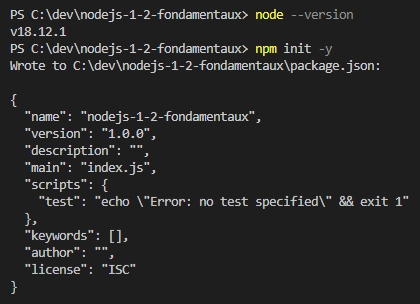
- Entrer la commande « nmp init -y » pour installer le package npm :
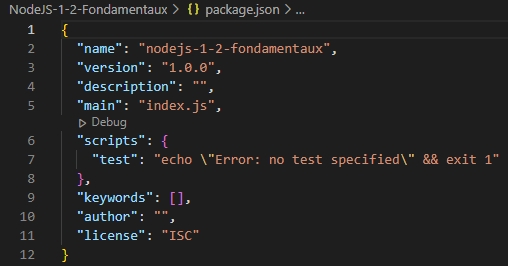
- Dans la partie gauche de la fenêtre VSCode, sélectionner le répertoire de la formation. Le fichier « package.json » comportant les paramètres de notre projet doit être présent. Le sélectionner pour visualiser son contenu.
- Premier exemple : Ajouter un fichier « index.js » à l’intérieur du répertoire projet. Ajouter y le code suivant :
var a = 1;
var b = 2;
console.log("a + b = ", (a+b));Exécuter le script dans la fenêtre terminal : « node index.js ». le résultat « a + b = 3 » doit s’afficher.
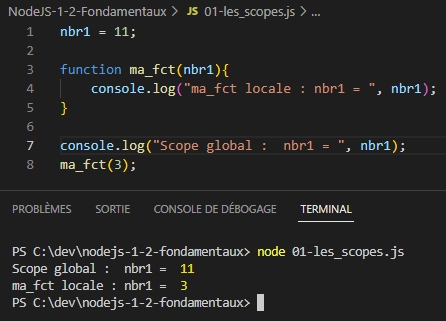
Un scope est un ensemble où les variables et les fonctions sont accessibles entre elles. Un scope peut être local ou global.
Il existe une syntaxe un peu spéciale qui permet d’exécuter une fonction anonyme : il faut englober la fonction anonyme dans des parenthèses. l’ensemble devient donc une fonction que l’on peut exécuter en ajoutant une paire de parenthèses à la fin. (Note: N’oubliez pas le point virgule final, son absence provoquant parfois des erreurs).
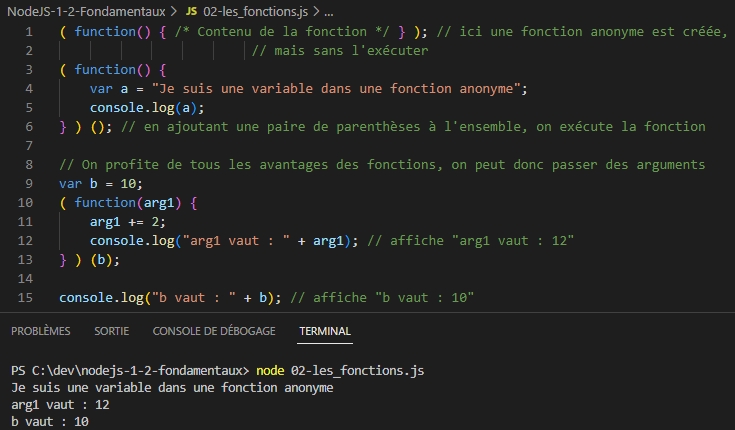
Une solution est d’affecter la fonction à une variable et d’utiliser des parenthèses. C’est les parenthèses qui provoquent l’appel de la fonction. On dit aussi l’invocation de la fonction.
Pourquoi faire ainsi ? On aura besoin de déclarer des fonctions de cette manière quand on travaillera avec des gestionnaires d’événements.
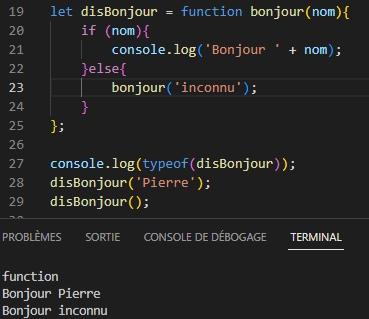
Le langage JavaScript possède un mécanisme de gestion des fonctions particulier appelé closure. Les closures se basent sur des fonctions dites de première classe. Ce sont des fonctions qui peuvent être stockées dans des variables, envoyées dans d’autres fonctions ou retournées comme résultat d’une fonction.
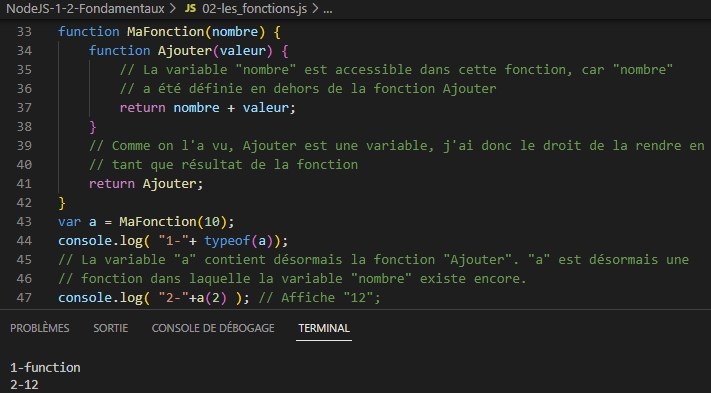
Lorsque vous utilisez le mot-clé function pour créer une fonction dans une fonction, alors vous êtes en train de créer une closure. Une closure est la pile de mémoire associée à une fonction. Cette pile mémorise les variables locales utilisées par la fonction au moment de sa destruction. Dans la plupart des langages de programmation, lorsque l’exécution d’une fonction se termine, les variables locales de la fonction sont détruites. Ce n’est pas le cas en JavaScript : elles sont sauvegardées dans une closure.
function MaFonction(nombre) {
function Ajouter(valeur) {
// La variable "nombre" est accessible dans cette fonction, car "nombre"
// a été définie en dehors de la fonction Ajouter
return nombre + valeur;
}
// Comme on l'a vu, Ajouter est une variable, j'ai donc le droit de la rendre en
// tant que résultat de la fonction
return Ajouter;
}l faut également savoir que les variables sauvegardées ne sont pas copiées, ce sont des références.
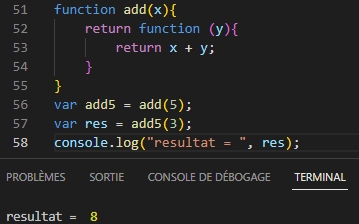
Cas d’exemple 1:
Exemple 2 :
Node.js, contrairement à d’autres plateformes, est monothreadé c’est-à-dire qu’un seul thread est utilisé pour traiter toutes les requêtes et opérations. On peut donc penser que ce n’est pas très efficace, mais Node.js tire sa force de son architecture événementielle et asynchrone, on dit aussi que Node.js est non bloquant.
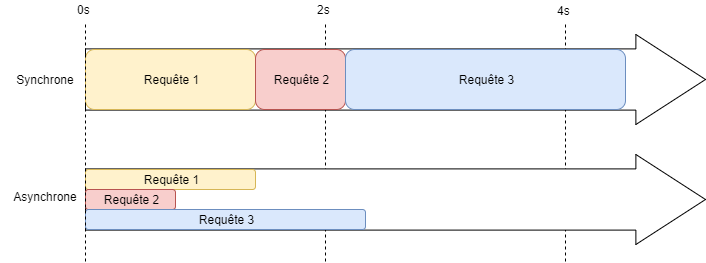
Imaginons que notre programme exécute des requêtes en base de données. Dans le modèle synchrone, le programme exécute une requête et doit attendre que le système de gestion de base de données lui retourne le résultat avant de passer à la requête suivante. Dans le modèle asynchrone, cette fois-ci le programme n’a pas besoin d’attendre le résultat d’une requête avant d’exécuter la suivante, une fois le résultat de la requête retourné au programme, celui-ci effectue les actions qu’on lui avait demandées (via des fonctions de callback par exemple) . De manière générale pour toutes interactions extérieures au programme (entrées/sorties), Node.js utilise l’asynchrone. Par exemple :
- Requête HTTP,
- Requête en base de données,
- Lecture/écriture de fichiers sur le disque dur,
- Envoi d’emails
- etc.
Par contre en JavaScript, chaque ligne de code est exécutée de façon synchrone, mais il est possible de demander à exécuter du code de manière asynchrone. Et lorsque l’on demande à exécuter une fonction de façon asynchrone, la fonction en question est placée dans une sorte de file d’attente qui va exécuter toutes les fonctions qu’elle contient les unes après les autres. C’est ce qu’on appelle l’event loop. Tout le cœur du langage fonctionne autour de ça.
Ainsi, le code n’est pas réellement exécuté en parallèle car il est mis en file d’attente, mais il ne bloque pas l’exécution du code depuis lequel il a été appelé.
Exemple du fonctionnement de « l’even loop » :
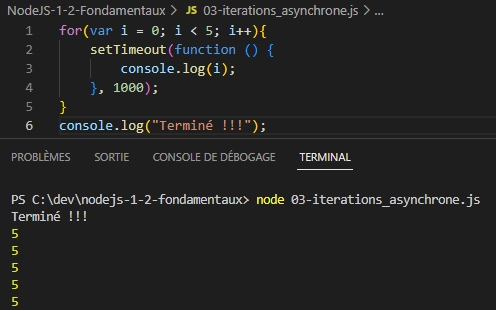
On remarque que la fonction « setTimeout » fonctionne nativement en mode asynchrone.
Pour faire fonctionner le comptage de boucle en mode synchrone, on utilise une astuce qu’il faut retenir car elle peut être appliquée à d’autre problèmes du même type :
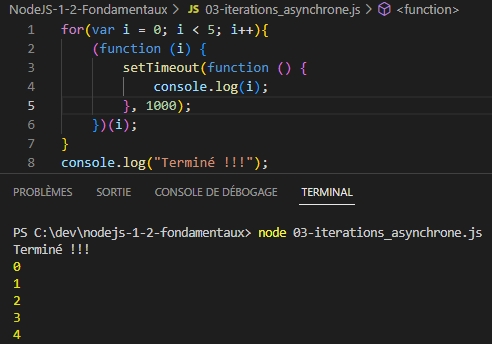
Il faut positionner la fonction asynchrone dans une fonction anonyme auto-appelante.
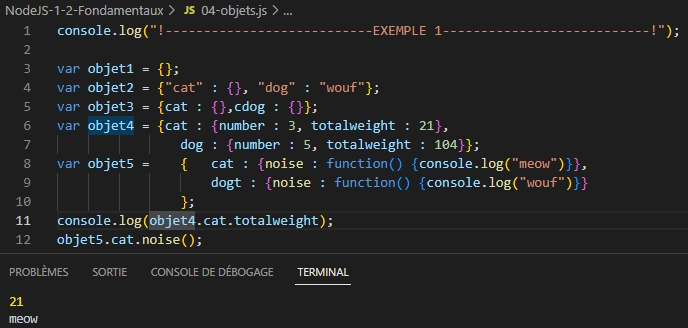
Les objets natifs
En Javascript, les objets natifs sont définis en utilisant les accolades. Un objet peut contenir d’autres objets. Les objets possèdes des attributs (dans notre exemple : cat et dog). Ils peuvent contenir des fonctions.
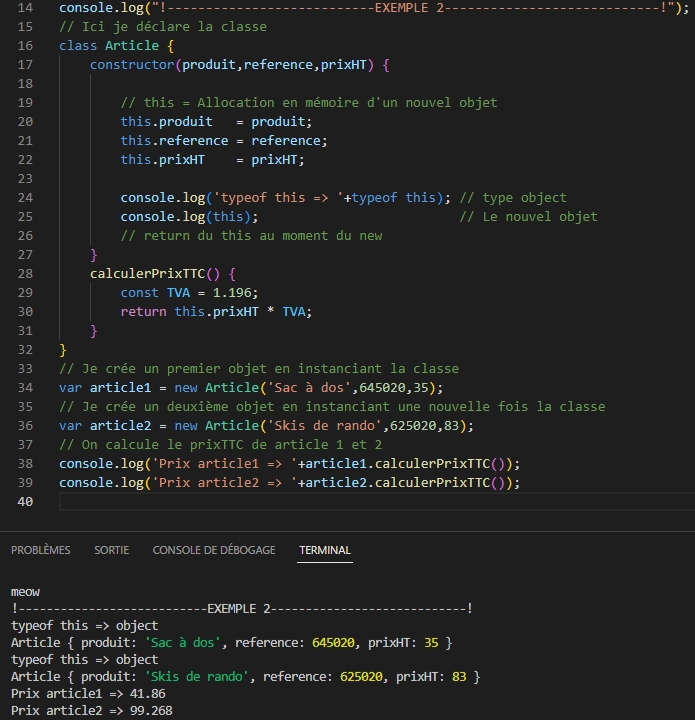
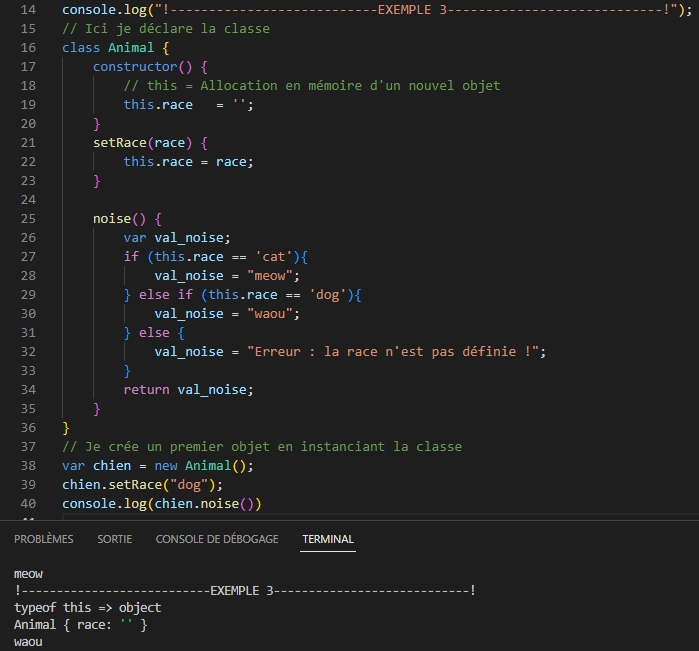
Les objets instanciés
Les objets instanciés proviennent d’une class. Quand on créé la class (new), un objet est instancié.
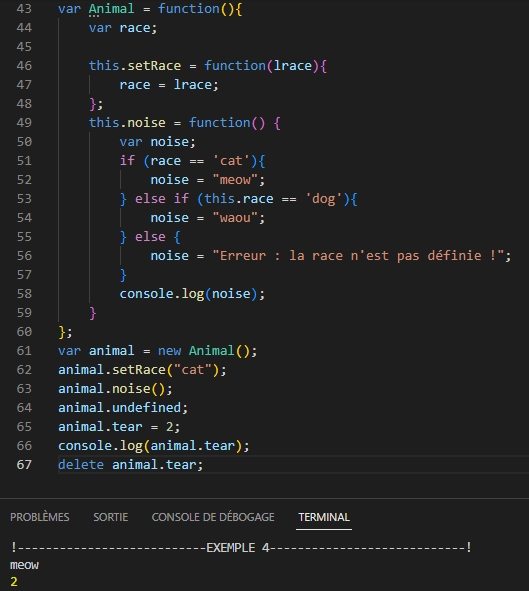
Une autre manière de coder cet exemple sans utiliser la l’attribut « class ».
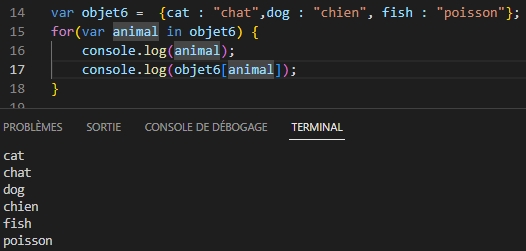
Enumérer les propriétés
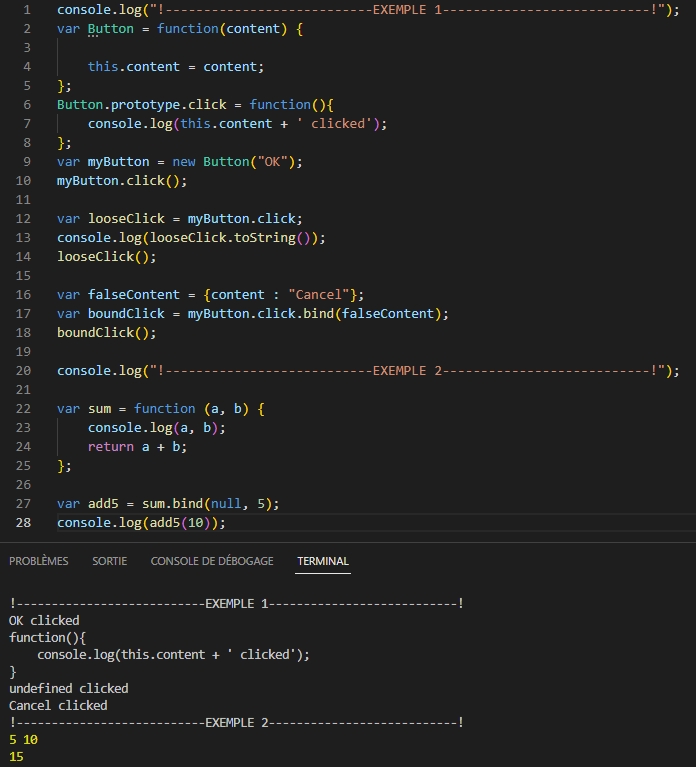
Le contexte et this
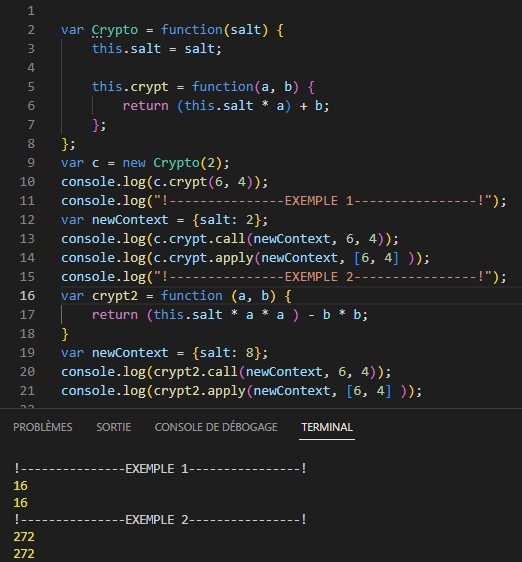
Le contexte est un objet spécifique à Javascript qui peut être instancié et qui reçoit, en début d’interprétation du code, une série de propriétés utilisables à travers l’ensemble du code.
A chaque instanciation d’objet est créée un nouveau contexte.
On peut accéder au contexte grâce au mot ‘this’.
Avec Javascript, la fonction « bind() » permet d’attacher un contexte à la fonction appelée, mais aussi de paramétrer la fonction appelée avec des arguments en dur.
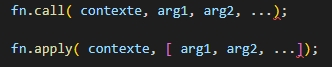
Apply et Call sont deux fonctions qui peuvent être appelées à chaque fonction.
Elles permettent d’appeler la fonction avec les arguments en argument.
Apply et Call vont appeler une fonction en lui insérant sont propre contexte avec des arguments en supplément.
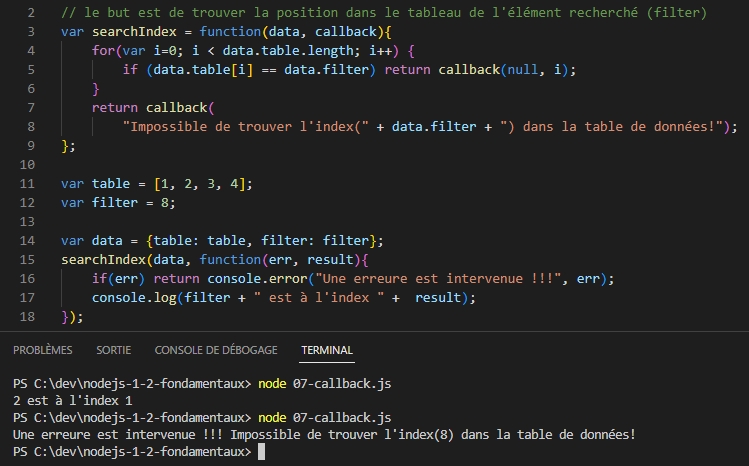
Les callbacks sont des fonctions appelées à la fin d’une tâche. Elle peuvent aussi être désignées par abus de langage, comme étant une fonction anonyme passée en argument.
Une très grande partie du Code de NodeJS est développé avec des callbacks.
Cas d’exemple : On veur lancer une recherche à partir d’une fonction avec les arguments :
- les données et le filtre
- la callback
Dans la fonction, après avoir terminé de traiter les données, on appelle la fonction callback avec les potentielles erreurs et le résultat. Par convention, le premier argument renvoyé est l’erreur, le second le résultat.
Les méthodes synchrones et asynchrones
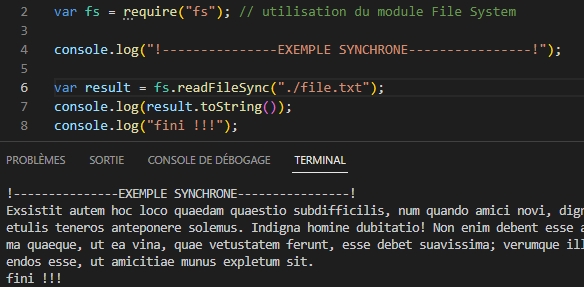
Mode synchrone : Dans le cas d’un gros fichier de plusieurs Moctets, le pointeur d’exécution du programme reste « coincé » sur la commande readFileSync.
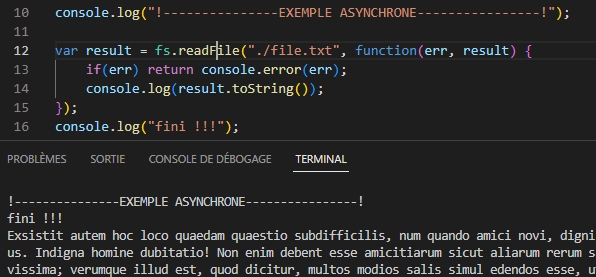
En mode asynchrone, avec deux fichiers, les relectures sont exécuté en même temps. On est averti lorsque l’un puis l’autre des lectures sont terminées. Le programme ne reste pas bloqué sur une tâche lourde.
Dans l’exemple ci-dessous, on constate que « fini !!! » est affiché avant l’affichage du fichier.
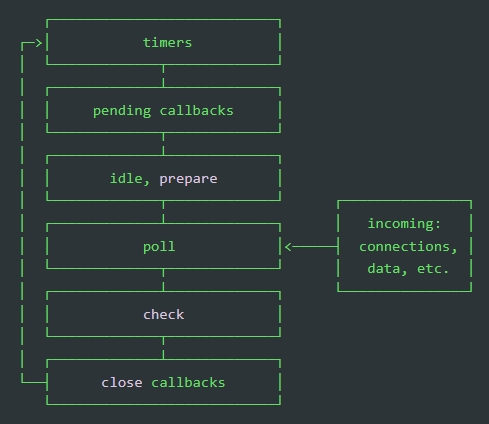
- timers : Exécute les callbacks (rappels planifiés) des fonctions setTimeout et setInterval;
- pending callback (rappels en attente) : Cette phase exécute les callbacks de certaines opérations systèmes comme les erreurs TCP par exemple.
- idle, prepare (inactif, préparer) : utilisé uniquement en interne.
- poll : récupérer de nouveaux événements d’E/S ; exécuter des rappels liés aux E/S (presque tous à l’exception des rappels de fermeture, ceux planifiés par les timers, et setImmediate()) ; Si tout les callbacks de cette phase ont été exécutés et qu’il n’y a pas de tâches en attente (callbacks d’autres phases ou timers) plutôt que de parcourir les différentes phases inutilement, la boucle d’événements reste dans cette phase en attentes de nouveaux événements externes;
- check : Exécute les callbacks de la fonction setImmediate.
- callbacks de fermeture : certains callbacks de fermeture, par exemple socket.on(‘close’, …).
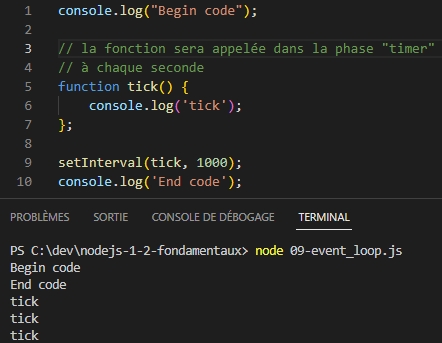
Exemple 1 :
Exemple 2 : Blocage !!!
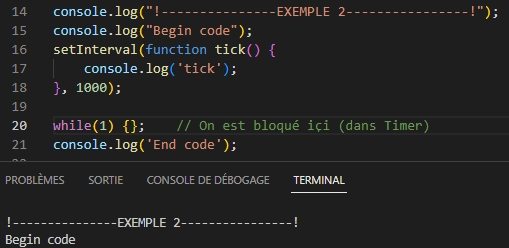
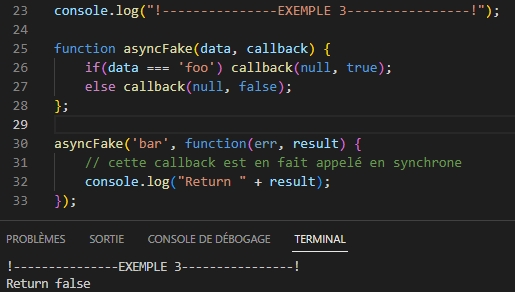
Exemple 3 : L’appel à la fonction est lancée en mode asynchrone, mais en réalité le déroulement de l’exécution se comporte en séquentiel : c’est du synchrone !
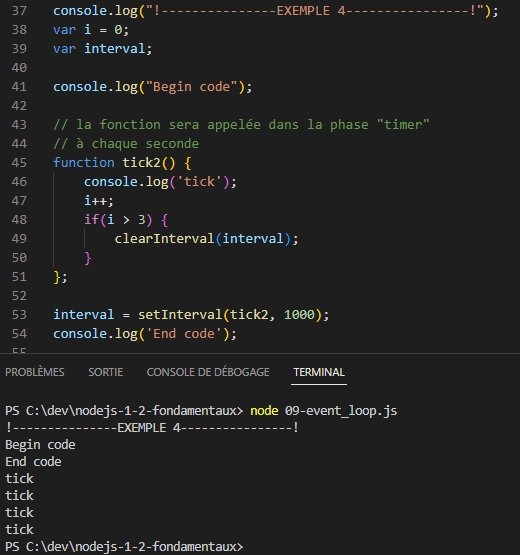
Exemple 4 : On compte 4 tics puis on delete le timer.
En conclusion : NodeJS est mono-threader et fonctionne en mode synchrone. Seule les fonctions système d’entrées-sorties sont asynchrones.
Sujet : Programmer une fonction qui va télécharger 3 images en même temps (téléchargement asynchrone). Une fois que les trois images sont téléchargées, afficher un message avec la taille totale des 3 images.
Algorithme :
- On créé un array qui contient nos trois images,
- on appelle une fonction qui gèrera les trois téléchargements,
- on lance les trois téléchargements. Dans leur callback, on compte le nombre de retours et on garde la taille de l’image téléchargée,
- Une fois qu’il y a eu trois callbacks de retour, on appelle la callback pour indiquer que l’on a téléchargé nos trois images, et on affiche le résultat.